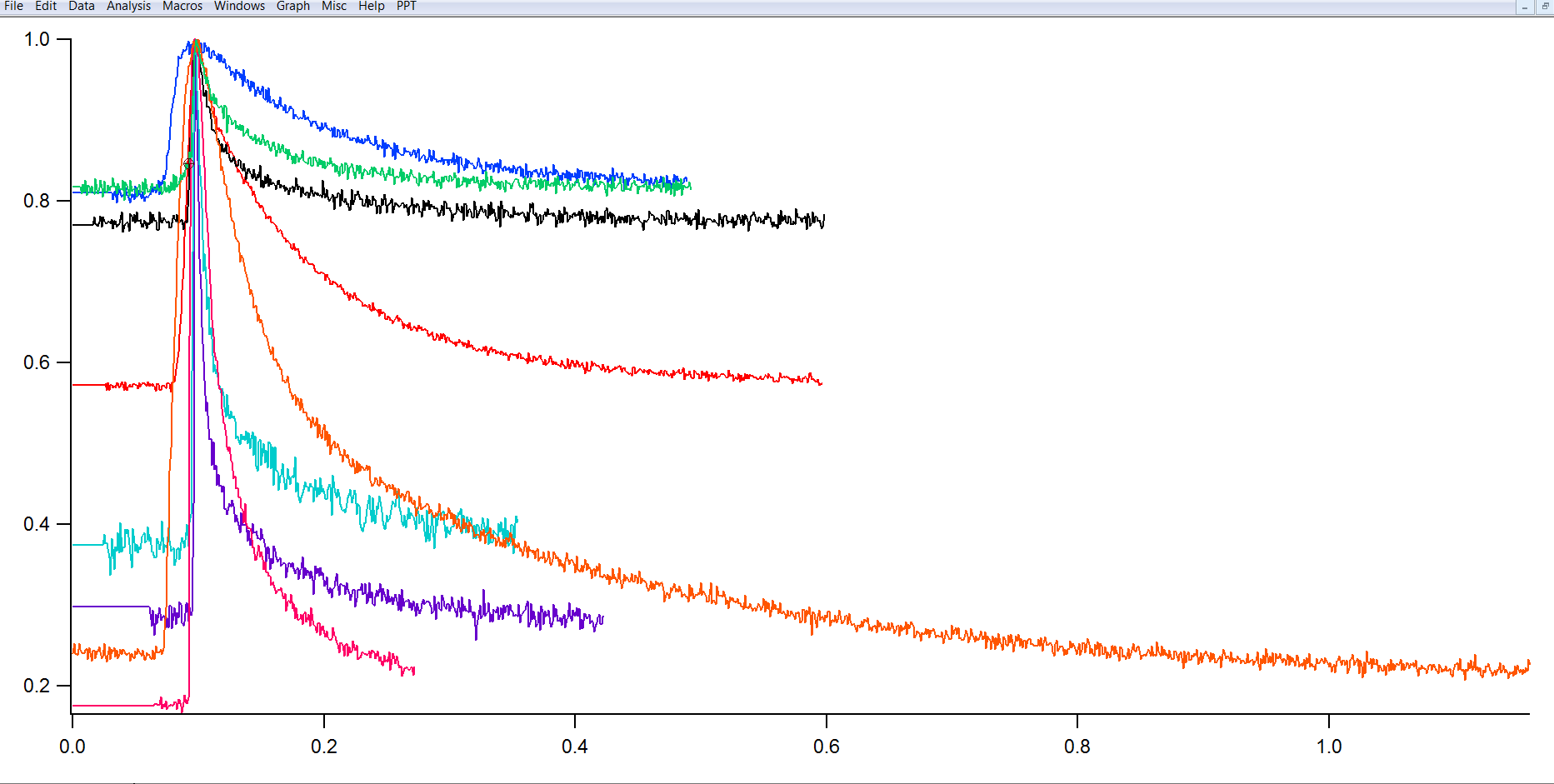
First I'd recommend normalizing all the waves so that the baseline is at 0 and the peak is at 1. Right now there's some pretty significant vertical offsets, so averaging the waves is going to give you nonsense due to that nonzero baseline. This is relatively easy to do using the Wave Arithmetic panel under Analysis-Packages-Wave Arithmetic.
Once they're normalized, there's another package that can give you the average. If all the waves are in the same plot like you've shown, just use the Average Waves package, also under Analysis-Packages-Average Waves.
After you have the average, you'll want to fit the average to your rising/falling exponential function. Go to Analysis-Curve Fitting..., then make a New Fit Function... for your function. You might start with just the falling exponential, using the cursors to select just the falling part of the data to get some reasonable guesses.
I would suggest to go the other way round: Find a fit function that uses a vertical offset, a time offset, and an amplitude f(t)=y0+A*(1-(exp(...(t-t0)...) etc. and average the obtained and relevant parameters afterwards (I guess the time constants). No need for manual normalization and peak shifting necessary in this case. In addition you can estimate whether an averaging would be meaningful (scatter of the fit parameter results).
Thanks, I went the normalizing route and aligned the waves by first point of rising phase before computing the average of N waves.
I stand with HJ Drescher on this. What you did may be the easier option to perform in practice. I am unconvinced that it is the more robust option to do in principle. I suspect if not insist, the better option in principle is to define a fitting function that includes a baseline offset and/or height normalization factor (and starting point offset), fit each curve separately to the overall function, extract the array of time constant values with their standard uncertainties, and then do a weighted average of the array of values to compute an overall value and its uncertainty for each time constant.
When this would be published and I would be a reviewer, you might have to convince me otherwise that you normalized and aligned your waves in a robustly objective way (i.e. not "visually by the maximum and minimum values or otherwise by whatever 'looked good'").
--
J. J. Weimer
Chemistry / Chemical & Materials Engineering, UAH
I do agree with HJ and JJ that if the primary goal is to get the time constants, it's better to fit each wave individually then average the various values you get. That way you can also extract some uncertainty from the values that you'll lose just by doing my method of normalizing + averaging. If you do go that route, let us know how well the two approaches agree!
My motivation for waveform averaging is to determine the best representation of N waveforms by finding their average. The background story is that, I need to design software that can automatically determine such representations of the data without expecting the user to input any sort of initial values for activities such as curve fitting. In short, I want this to be done in as automated a manner as allows. I appreciate any more feedback from the users ! Let us discuss further. Thanks.
My motivation for waveform averaging is to determine the best representation of N waveforms by finding their average. The background story is that, ...
OK. This is a different story than what I anticipated. I apologize for the misunderstanding. However, I am still confused about the end use. Let me fill in the blanks ...
I imagine that you have a signal being generated at different conditions. The differences cause a change in intensity (offset and scale) and a shift in time. Regardless of the practical conditions, the two time constants that fit the curves should always be the same in principle.
You want to design a way for a user to run multiple sample curves and get a representative "average" of the time constants. Certainly, the method you have chosen to pre-normalize and pre-shift is a good way to build a "quick and dirty" UI for users.
Eventually, I would recommend that you fit each raw data curve using its own merit function without pre-normalization and shifting. Build the normalization and shift into the fitting function itself as fitting parameters. After the fit, extract only the time constants and their standard uncertainties. For each raw data curve that is acquired, store each new set of time constant value sequentially in waves, for example tcrise, tcdecay, dtcrise, dtcdecay (for the rise and decay time constants and their standard uncertainties). Then, recompute a new average for the time constants.
Here's an example of how to calculate the average of the time constant in a rigorous manner when given a wave of time constants (tc) and a wave of their standard uncertainties (dtc).
whats the best way to make the waves go from 0 to 1?
I merely subtracted the minimum and then divided by the new maximum. Is that a good method ?
@jjw thanks for your input , the time constants are variable , amplitudes are also variable and diverse. Fitting each curve may not be feasible because the end user cannot be expected to spend long hours guessing and fitting data. Thanks again !
It's really not hard to fit each set of data individually before doing the averaging. First, note that your f(t) can be rearranged to be the convolution between two exponentials:
f(t) = exp(-t/decaytimeconstant)-exp[-t*(1/risetimeconstant+1/decaytimeconstant)] = exp(-k1*t)-exp(-k2*t)
Luckily, ExpConvExp is included as a type of peak in the Analysis - MultiPeakFitting 2 package. That package is also pretty fantastic at auto-guessing peaks and parameters, so it doesn't take "hours" of fiddling to get a good fit. I highly recommend familiarizing yourself with the Multi-Peak fitting package by trying it on some of your waves. The Help button has a pretty comprehensive set of documentation.
What's more, there's built-in functionality to automatically fit a bunch of waves using the MPF2 package. For example, if you wanted to fit wave0, wave1, and wave2 to the ExpConvExp peak type, first load the package then enter this at the command line:
The result will be a set of data folders PeakResult_0, PeakResult_1, and PeakResult_2 that contain the wave PeakCoefs0. The four coefficients are Location, Height, k1, and k2. Of course you can modify the inputs as needed; documentation is in that "help" button.
You would need to create a procedure to generate the list of waves, possibly using the function TraceNameList("",";",0), then call the MPF2_AutoMPFit() function, then dig through all the PeakResult_n folders to extract the various fitted coefficients. Not too bad.
I did observe that the average "risetimeconstant", "decaytimeconstant1","decaytimeconstant2" for double exponentially decaying waves, derived from individual fits is quite different than the time constants derived from averaging the waves and fitting only average wave. Is there any particular reason for this anomaly? Whereas the average rise and decay time constants for single exponential decay aligned well with those obtained by fitting the average of waves.
I did observe that the average "risetimeconstant", "decaytimeconstant1","decaytimeconstant2" for double exponentially decaying waves, derived from individual fits is quite different than the time constants derived from averaging the waves and fitting only average wave.
I suspect that by averaging the waves you are significantly distorting the overall shape, and the double exponential decay would be more sensitive to that distortion than the single exponential. It probably depends highly on how you do the offset and normalization before averaging -- which is why it's better to do the fits first before the average as others have pointed out.
whats the best way to make the waves go from 0 to 1?
I merely subtracted the minimum and then divided by the new maximum. Is that a good method ?
AG gives the best answers here when you want to use the min/max approach. My concern with using the min/max approach is this: It is not statistically valid because your raw signal has noise. Consider when your data has a spike. Your normalization will be thrown off dramatically.
Supriya Balaji wrote:
@jjw thanks for your input , the time constants are variable , amplitudes are also variable and diverse. Fitting each curve may not be feasible because the end user cannot be expected to spend long hours guessing and fitting data. Thanks again !
Well, I am totally confused by this response against the history of your responses. First, even after the data are normalized, the fitting still requires some "guess work". Why is this any more difficult. Secondly, with some careful pre-programming, you can design code that will pre-fit the curves with a set of "first guess" parameters in order to minimize the need for a user to have to play around on their own. Finally, you first said that you want to average curves to get average time constants. Then you say, the time constants vary from scan to scan. Now, you also say this ...
Supriya Balaji wrote:
I did observe that the average "risetimeconstant", "decaytimeconstant1","decaytimeconstant2" for double exponentially decaying waves, derived from individual fits is quite different than the time constants derived from averaging the waves and fitting only average wave. Is there any particular reason for this anomaly? Whereas the average rise and decay time constants for single exponential decay aligned well with those obtained by fitting the average of waves.
As @ajleenheer notes, the reason you get strange results is because the run-to-run curves WHICH ARE DIFFERENT FOR EACH RUN (my emphasis) are totally distorted by averaging.
Let's try a different approach to help you. Can you explain the code you are trying to create from a user's perspective. For example ...
* The user clicks a button to capture a raw data curve.
* The user clicks a button to fit that curve to a function. The fitting parameters are reported and stored.
* The user repeats the process N times.
* The user clicks a button to get "average" or "best-overall-fit" parameters from the N runs.
Is this what you want to design? Or do you have something else in mind?
--
J. J. Weimer
Chemistry / Chemical & Materials Engineering, UAH
1) User chooses a few spikes(about 10) from a large data trace consisting of ~100 spikes or more
2) Program will subtract baseline, normalize spikes by amplitude and then cluster them into less than 5 groups based on their similarities to each other
(The spikes in any one cluster are similar to each other,and yes, their time constants are very slightly different but not widely varying from each other.)
4) Each cluster will now be averaged to find the Wave_Average. Program will use pre-set guesses to fit the average wave with the following function
5) The reason I want to stay away from fitting all spikes is , to make this process as user-independent as possible. Even pre-set initial guesses will involve user-intelligence and while it is unavoidable, I want to reduce the incidence of user-inputs.
What is your advice on baseline subtraction and averaging ? I tried to subtract the mean of a spike-free , noisy region and got good results. Attached is the normalized spike image showing the region that i originally used to subtract baseline. Thanks for your interest !
If the time constants aren't too different, then averaging your data sets will probably work out. But please note that averaging is just a normalized sum. If you add together two exponentials with different time constants, you wind up with a double exponential decay. It's not really suitable now to fit it with a single exponential term.
I also think that if you know a priori that the data sets will always have a peaked shape (a decay upward to the peak plus a decay downward to the baseline; double exponential with opposite amplitudes) it shouldn't be too terribly hard to write a routine to automatically generate the initial guesses. Then you can have a fully automated way to do multiple fits without involving the user.
Now that you've explained you have a "spike" train as raw data, I really recommend the Multi-peak fitting data package. I've attached an image simulating what I think you're doing; the part that took me the longest was generating the fake data.
Igor does a good default job at auto-guessing Gaussian peaks as long as your signal-to-noise ratio is decent. The tricky part is converting those Gaussian guesses to the exponential rise/decay. The Multi Peak Fitting package takes the gaussian amplitude and width and translates those into starting guesses for the ExpConvExp function (which in your case includes just the single exponential decay function). In my test, those guesses were sufficient to get a good fit to all the peaks when I hit "do fit." But, I suspect that if you know what your data generally looks like, you could tweak how it converts from Gaussian guesses to the ExpConvExp guesses. That conversion is done in the function GaussToExpConvExpGuess(w) in the PeakFunctions2 procedure window.
If the double-exponential decay is critical to you, you'd have to write your own function for the Multi Peak Fitting routine to use. Let me know if you need help with that. I'd take a three-step approach: (1) let Igor auto-find the Gaussian peaks using the Multi-Peak Fitting package; (2) convert those gaussian peaks to ExpConvExp peaks and do that fit; (3) convert the k1 and k2 fitting constants as reasonable guesses for your "risetimeconstant" and "decaytimeconstant" values that feed into your custom peak function, and do the final fit.
You don't have to do this from the Multi-Peak fitting GUI; with a bit of work, you can call the Multi Peak Fitting routines from its functions for programmers as I alluded to above.
In this approach, you get all the fitted constants for all the peaks. After the fact, if it's important to you, you can bin them by similarity, average them, graph the average, etc. But you avoid the nonsense of trying to extract data out of a bunch of peaks that have been offset, normalized, and averaged, perhaps incorrectly due to the noise.
1) User chooses a few spikes(about 10) from a large data trace consisting of ~100 spikes or more
This can be programmed to be automatic. Use the FindPeak or FindLevels operations to get a set of 100 positions. Then, use a random number generator to pick a starting point and select the peaks 1, 3, 5, 7, 11, 13, 17, 19, 23, and 37 from that position. You have your set of 10 randomly chosen spikes.
With no problem, the routine could then be designed to churn through the 100 spikes and analyze the whole "spectrum" rather than a random selection.
Alternatively, perhaps you need the user to select the 10 spikes because they truly need to be "different" from each other (rather than just random). In this case, you might consider to oversample the set, for example by choosing a random of 30 spikes (three times the 10 that you would have the user select).
Supriya Balaji wrote:
2) Program will subtract baseline, normalize spikes by amplitude and then cluster them into less than 5 groups based on their similarities to each other
(The spikes in any one cluster are similar to each other,and yes, their time constants are very slightly different but not widely varying from each other.)
What is meant my "similarities to each other"? Why five groups? Why bother normalizing?
Supriya Balaji wrote:
4) Each cluster will now be averaged to find the Wave_Average. Program will use pre-set guesses to fit the average wave with the following function
Again, why bother normalizing first? Why average the clusters rather than fitting each spike in the cluster and averaging (rigorously) the fitting constants?
Supriya Balaji wrote:
5) The reason I want to stay away from fitting all spikes is , to make this process as user-independent as possible. Even pre-set initial guesses will involve user-intelligence and while it is unavoidable, I want to reduce the incidence of user-inputs.
Everything above can be programmed to be done automatically without normalizing the spikes and averaging within clusters. As I note, even the selection of 10 or so spikes can be programmed. In the end, the routine can do this ...
* User clicks a button to collect a set of 100 (or so) spikes
* User clicks a button to process the spikes automatically ...
- software selects 10 random spikes
- software computes fitting constants from 10 random spikes, clusters the spikes, and computes averages for clusters
- software returns a report of values
* User repeats either of the above clicks
Supriya Balaji wrote:
What is your advice on baseline subtraction and averaging ? I tried to subtract the mean of a spike-free , noisy region and got good results. Attached is the normalized spike image showing the region that i originally used to subtract baseline.
When the fitting equation is designed properly, it will average over a baseline region. This is the right way to approach the problem.
So, in summary, I would note two comments.
* Nothing about your needs says that you need to continue with the normalizing and wave averaging method. Everything says that you can program the normalization in the fitting function and extract the average time constants in a more robust manner.
* Nearly everything you want to do can be programmed to minimize the need for user input.
--
J. J. Weimer
Chemistry / Chemical & Materials Engineering, UAH







{kind=link}
Once they're normalized, there's another package that can give you the average. If all the waves are in the same plot like you've shown, just use the Average Waves package, also under Analysis-Packages-Average Waves.
After you have the average, you'll want to fit the average to your rising/falling exponential function. Go to Analysis-Curve Fitting..., then make a New Fit Function... for your function. You might start with just the falling exponential, using the cursors to select just the falling part of the data to get some reasonable guesses.
June 22, 2016 at 01:29 pm - Permalink
HJ
June 22, 2016 at 03:17 pm - Permalink
June 28, 2016 at 06:44 am - Permalink
I stand with HJ Drescher on this. What you did may be the easier option to perform in practice. I am unconvinced that it is the more robust option to do in principle. I suspect if not insist, the better option in principle is to define a fitting function that includes a baseline offset and/or height normalization factor (and starting point offset), fit each curve separately to the overall function, extract the array of time constant values with their standard uncertainties, and then do a weighted average of the array of values to compute an overall value and its uncertainty for each time constant.
When this would be published and I would be a reviewer, you might have to convince me otherwise that you normalized and aligned your waves in a robustly objective way (i.e. not "visually by the maximum and minimum values or otherwise by whatever 'looked good'").
--
J. J. Weimer
Chemistry / Chemical & Materials Engineering, UAH
June 28, 2016 at 11:13 am - Permalink
June 29, 2016 at 07:33 am - Permalink
June 29, 2016 at 09:36 am - Permalink
OK. This is a different story than what I anticipated. I apologize for the misunderstanding. However, I am still confused about the end use. Let me fill in the blanks ...
I imagine that you have a signal being generated at different conditions. The differences cause a change in intensity (offset and scale) and a shift in time. Regardless of the practical conditions, the two time constants that fit the curves should always be the same in principle.
You want to design a way for a user to run multiple sample curves and get a representative "average" of the time constants. Certainly, the method you have chosen to pre-normalize and pre-shift is a good way to build a "quick and dirty" UI for users.
Eventually, I would recommend that you fit each raw data curve using its own merit function without pre-normalization and shifting. Build the normalization and shift into the fitting function itself as fitting parameters. After the fit, extract only the time constants and their standard uncertainties. For each raw data curve that is acquired, store each new set of time constant value sequentially in waves, for example tcrise, tcdecay, dtcrise, dtcdecay (for the rise and decay time constants and their standard uncertainties). Then, recompute a new average for the time constants.
Here's an example of how to calculate the average of the time constant in a rigorous manner when given a wave of time constants (tc) and a wave of their standard uncertainties (dtc).
--
J. J. Weimer
Chemistry / Chemical & Materials Engineering, UAH
June 29, 2016 at 01:39 pm - Permalink
I merely subtracted the minimum and then divided by the new maximum. Is that a good method ?
@jjw thanks for your input , the time constants are variable , amplitudes are also variable and diverse. Fitting each curve may not be feasible because the end user cannot be expected to spend long hours guessing and fitting data. Thanks again !
June 30, 2016 at 10:35 am - Permalink
That approach might work. Others include:
In this case you get both the minimum and maximum value in one scan through the data.
A less transparent but more efficient way is:
June 30, 2016 at 11:59 am - Permalink
f(t) = exp(-t/decaytimeconstant)-exp[-t*(1/risetimeconstant+1/decaytimeconstant)] = exp(-k1*t)-exp(-k2*t)
Luckily, ExpConvExp is included as a type of peak in the Analysis - MultiPeakFitting 2 package. That package is also pretty fantastic at auto-guessing peaks and parameters, so it doesn't take "hours" of fiddling to get a good fit. I highly recommend familiarizing yourself with the Multi-Peak fitting package by trying it on some of your waves. The Help button has a pretty comprehensive set of documentation.
What's more, there's built-in functionality to automatically fit a bunch of waves using the MPF2 package. For example, if you wanted to fit wave0, wave1, and wave2 to the ExpConvExp peak type, first load the package then enter this at the command line:
The result will be a set of data folders PeakResult_0, PeakResult_1, and PeakResult_2 that contain the wave PeakCoefs0. The four coefficients are Location, Height, k1, and k2. Of course you can modify the inputs as needed; documentation is in that "help" button.
You would need to create a procedure to generate the list of waves, possibly using the function TraceNameList("",";",0), then call the MPF2_AutoMPFit() function, then dig through all the PeakResult_n folders to extract the various fitted coefficients. Not too bad.
June 30, 2016 at 02:08 pm - Permalink
Thanks I have to try that.
to all users:
I did observe that the average "risetimeconstant", "decaytimeconstant1","decaytimeconstant2" for double exponentially decaying waves, derived from individual fits is quite different than the time constants derived from averaging the waves and fitting only average wave. Is there any particular reason for this anomaly? Whereas the average rise and decay time constants for single exponential decay aligned well with those obtained by fitting the average of waves.
Thanks
Supriya
June 30, 2016 at 02:48 pm - Permalink
I suspect that by averaging the waves you are significantly distorting the overall shape, and the double exponential decay would be more sensitive to that distortion than the single exponential. It probably depends highly on how you do the offset and normalization before averaging -- which is why it's better to do the fits first before the average as others have pointed out.
June 30, 2016 at 02:55 pm - Permalink
AG gives the best answers here when you want to use the min/max approach. My concern with using the min/max approach is this: It is not statistically valid because your raw signal has noise. Consider when your data has a spike. Your normalization will be thrown off dramatically.
Well, I am totally confused by this response against the history of your responses. First, even after the data are normalized, the fitting still requires some "guess work". Why is this any more difficult. Secondly, with some careful pre-programming, you can design code that will pre-fit the curves with a set of "first guess" parameters in order to minimize the need for a user to have to play around on their own. Finally, you first said that you want to average curves to get average time constants. Then you say, the time constants vary from scan to scan. Now, you also say this ...
As @ajleenheer notes, the reason you get strange results is because the run-to-run curves WHICH ARE DIFFERENT FOR EACH RUN (my emphasis) are totally distorted by averaging.
Let's try a different approach to help you. Can you explain the code you are trying to create from a user's perspective. For example ...
* The user clicks a button to capture a raw data curve.
* The user clicks a button to fit that curve to a function. The fitting parameters are reported and stored.
* The user repeats the process N times.
* The user clicks a button to get "average" or "best-overall-fit" parameters from the N runs.
Is this what you want to design? Or do you have something else in mind?
--
J. J. Weimer
Chemistry / Chemical & Materials Engineering, UAH
July 3, 2016 at 05:57 am - Permalink
Here is the intended design
1) User chooses a few spikes(about 10) from a large data trace consisting of ~100 spikes or more
2) Program will subtract baseline, normalize spikes by amplitude and then cluster them into less than 5 groups based on their similarities to each other
(The spikes in any one cluster are similar to each other,and yes, their time constants are very slightly different but not widely varying from each other.)
4) Each cluster will now be averaged to find the Wave_Average. Program will use pre-set guesses to fit the average wave with the following function
(1-exp(-t/risetimeconstant))*(Amplitude1exp(-t/decaytimeconstant1))+Amplitude2*exp(-t/decaytimeconstant2)) + Amplitude-baseline
5) The reason I want to stay away from fitting all spikes is , to make this process as user-independent as possible. Even pre-set initial guesses will involve user-intelligence and while it is unavoidable, I want to reduce the incidence of user-inputs.
What is your advice on baseline subtraction and averaging ? I tried to subtract the mean of a spike-free , noisy region and got good results. Attached is the normalized spike image showing the region that i originally used to subtract baseline. Thanks for your interest !
July 1, 2016 at 11:41 am - Permalink
I also think that if you know a priori that the data sets will always have a peaked shape (a decay upward to the peak plus a decay downward to the baseline; double exponential with opposite amplitudes) it shouldn't be too terribly hard to write a routine to automatically generate the initial guesses. Then you can have a fully automated way to do multiple fits without involving the user.
John Weeks
WaveMetrics, Inc.
support@wavemetrics.com
July 1, 2016 at 03:53 pm - Permalink
Igor does a good default job at auto-guessing Gaussian peaks as long as your signal-to-noise ratio is decent. The tricky part is converting those Gaussian guesses to the exponential rise/decay. The Multi Peak Fitting package takes the gaussian amplitude and width and translates those into starting guesses for the ExpConvExp function (which in your case includes just the single exponential decay function). In my test, those guesses were sufficient to get a good fit to all the peaks when I hit "do fit." But, I suspect that if you know what your data generally looks like, you could tweak how it converts from Gaussian guesses to the ExpConvExp guesses. That conversion is done in the function GaussToExpConvExpGuess(w) in the PeakFunctions2 procedure window.
If the double-exponential decay is critical to you, you'd have to write your own function for the Multi Peak Fitting routine to use. Let me know if you need help with that. I'd take a three-step approach: (1) let Igor auto-find the Gaussian peaks using the Multi-Peak Fitting package; (2) convert those gaussian peaks to ExpConvExp peaks and do that fit; (3) convert the k1 and k2 fitting constants as reasonable guesses for your "risetimeconstant" and "decaytimeconstant" values that feed into your custom peak function, and do the final fit.
You don't have to do this from the Multi-Peak fitting GUI; with a bit of work, you can call the Multi Peak Fitting routines from its functions for programmers as I alluded to above.
In this approach, you get all the fitted constants for all the peaks. After the fact, if it's important to you, you can bin them by similarity, average them, graph the average, etc. But you avoid the nonsense of trying to extract data out of a bunch of peaks that have been offset, normalized, and averaged, perhaps incorrectly due to the noise.
July 1, 2016 at 04:09 pm - Permalink
This can be programmed to be automatic. Use the FindPeak or FindLevels operations to get a set of 100 positions. Then, use a random number generator to pick a starting point and select the peaks 1, 3, 5, 7, 11, 13, 17, 19, 23, and 37 from that position. You have your set of 10 randomly chosen spikes.
With no problem, the routine could then be designed to churn through the 100 spikes and analyze the whole "spectrum" rather than a random selection.
Alternatively, perhaps you need the user to select the 10 spikes because they truly need to be "different" from each other (rather than just random). In this case, you might consider to oversample the set, for example by choosing a random of 30 spikes (three times the 10 that you would have the user select).
What is meant my "similarities to each other"? Why five groups? Why bother normalizing?
Again, why bother normalizing first? Why average the clusters rather than fitting each spike in the cluster and averaging (rigorously) the fitting constants?
Everything above can be programmed to be done automatically without normalizing the spikes and averaging within clusters. As I note, even the selection of 10 or so spikes can be programmed. In the end, the routine can do this ...
* User clicks a button to collect a set of 100 (or so) spikes
* User clicks a button to process the spikes automatically ...
- software selects 10 random spikes
- software computes fitting constants from 10 random spikes, clusters the spikes, and computes averages for clusters
- software returns a report of values
* User repeats either of the above clicks
When the fitting equation is designed properly, it will average over a baseline region. This is the right way to approach the problem.
So, in summary, I would note two comments.
* Nothing about your needs says that you need to continue with the normalizing and wave averaging method. Everything says that you can program the normalization in the fitting function and extract the average time constants in a more robust manner.
* Nearly everything you want to do can be programmed to minimize the need for user input.
--
J. J. Weimer
Chemistry / Chemical & Materials Engineering, UAH
July 3, 2016 at 05:57 am - Permalink
July 7, 2016 at 07:12 pm - Permalink